
Si jamais vous constatez un article (ou plusieurs) qui n’est pas censé être dans un de vos dossiers (du fait de sa langue, son contenu, sa date, ou autre), ou qu’un site semble remonter régulièrement des actualités erronées, cette page doit vous aider à comprendre pourquoi.
Si vous êtes administrateur Scan, vous avez accès à l’administration des articles et vous avez donc des outils supplémentaires pour comprendre pourquoi un article est présent dans les ACTUALITÉS d’un dossier. Rendez-vous sur cette page pour en savoir plus (tous les cas décrits dans la page ci-présente sont plus faciles à analyser en utilisant l’administration des articles).
On part de l’exemple ou vous auriez repéré un article problématique dans un de vos dossiers.
Cas 1 : la requête du dossier matche « normalement » avec l’article
Votre dossier est par exemple paramétré avec la requête Iot | « objets connectés » et l’article en question s’affiche dans l’onglet « ACTUALITÉS » de la façon suivante :

Le « snippet », c’est à dire l’extrait de l’article qui matche la requête nous montre bien que l’article contient un des éléments de la requête, ici l’expression « objets connectés » : … cerveau-machine multimodales (ICMs) permettent d’offrir aux personnes en situation de handicap la possibilité de contrôler des objets connectés et des environnements numériques grâce à ces commandes mentales, sans interactions physiques ou vocales …
Si jamais vous êtes en affichage « compact », vous pouvez passer la souris sur l’article afin de voir le snippet :

Il n’y a donc techniquement pas de problème au fait que l’article s’affiche dans le dossier. Cependant, ça peut être l’occasion de voir qu’une expression de la requête n’est pas correcte ou qu’elle ramène trop de bruit (il manque une option exact ou un = devant un mot ou une expression par exemple). Retrouvez l’aide du mode EXPERT ici ou celle du mode BLOCS ici.
Il est possible que le « snippet » montre un extrait correct par rapport à votre requête mais que sur la page web de l’article vous ne retrouviez pas cet extrait. Dans ce cas il peut s’agir de texte qui a été pris à l’extérieur de l’article dans la page (dans un cadre qui change régulièrement ou dans une liste d’articles liés par exemple) et il faut effectuer un correctif. Il est également possible que l’extrait proposé soit dans un morceau de texte qui n’appartient à priori pas du tout au contenu de l’article (Cf. exemples fournis dans le paragraphe suivant « Cas 2 »). Dans ces deux cas particuliers, n’hésitez pas à ouvrir l’article, puis cliquez sur le bouton SIGNALER dans la barre d’action en haut :

Cela permettra à un administrateur de corriger les pages du site en question afin que le problème ne se reproduise pas sur cette source.
Cas 2 : Découpage de la page erroné
Il arrive que le contenu texte d’un article soit mal extrait de la page web d’origine. Malheureusement avec des millions de sites Scan ne peut pas être paramétré parfaitement pour chacun d’entre eux, mais ce type de problème peut être corrigé facilement. Voici quelques exemples qui doivent vous faire comprendre que le site est « mal découpé ».
Exemple « voir aussi » / « à lire également » :
La requête contient cyberguerre et on voit plein d’articles d’un même site qui matchent, avec à chaque fois le même – ou quasiment le même – extrait (aussi appelé « snippet ») :

Cela signifie que chaque article reprend une liste de liens associés et qu’il faut corriger le découpage des pages du site.
Autre version plus subtile, ici la requête du dossier est « informatique quantique » :
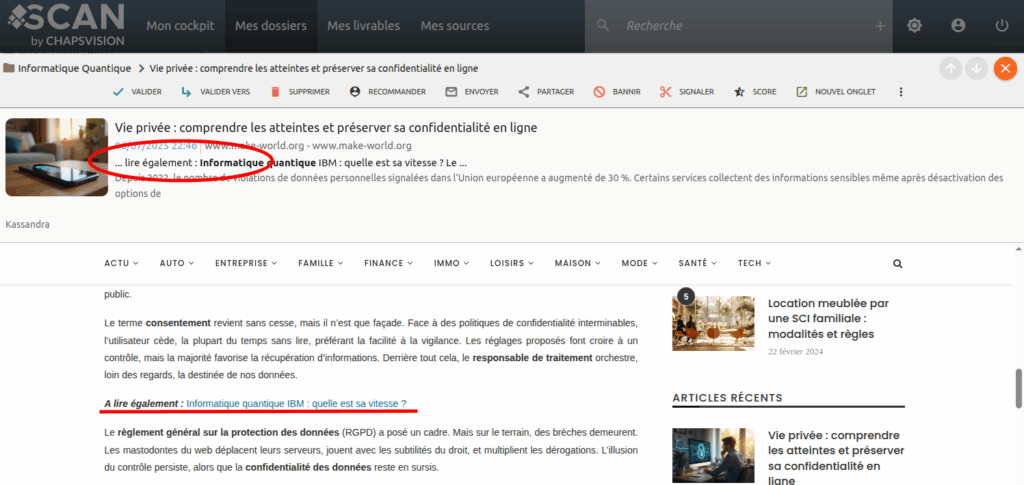
On voit dans l’extrait qui matche que l’expression est trouvée à proximité d’un « lire également », et, si on ouvre l’article, on voit que le texte qui matche est une référence vers un autre article qui peut apparaître au sein même du texte de l’article en question ou juste après.
Exemple « Menus » :
On peut parfois voir qu’un site est mal découpé car des morceaux de la requête matchent avec certains Menus de la page :

Dans les cas présentés ici en exemple ou tout autre cas approchant (le corps de l’article semble mal récupéré), n’hésitez pas à cliquer sur le bouton SIGNALER dans la barre en haut d’un article ouvert :
Cela permettra à un administrateur de corriger les pages du site en question afin que le problème ne se reproduise pas sur cette source.
Cas 3 : Langue mal détectée
Exemple simple : vous n’avez coché que la langue « français » dans les paramètres du dossier mais un article en anglais apparaît dans les ACTUALITÉS.
Il est possible que la langue soit mal détectée par Scan. En effet, Scan récupère environ 1 million d’actualités par jour, dans cette masse il peut parfois y avoir des problèmes de détection de langue.
Vous pouvez supprimer l’article de votre dossier pour qu’il n’apparaisse plus. Vous pouvez également signaler le problème au support ChapsVision (Cf. page Contact) pour qu’il fasse un correctif sur la source associée et que le problème ne se reproduise pas sur ce site.
Vous pouvez si vous le souhaitez bannir le site en indiquant « Langue du site non choisie » dans les raisons du bannissement :
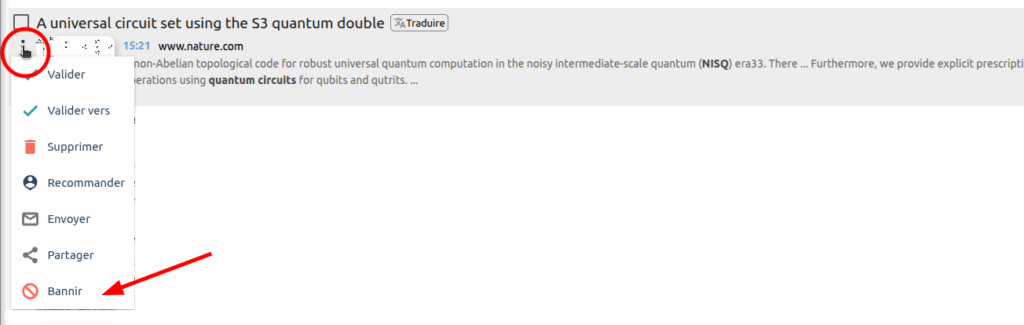
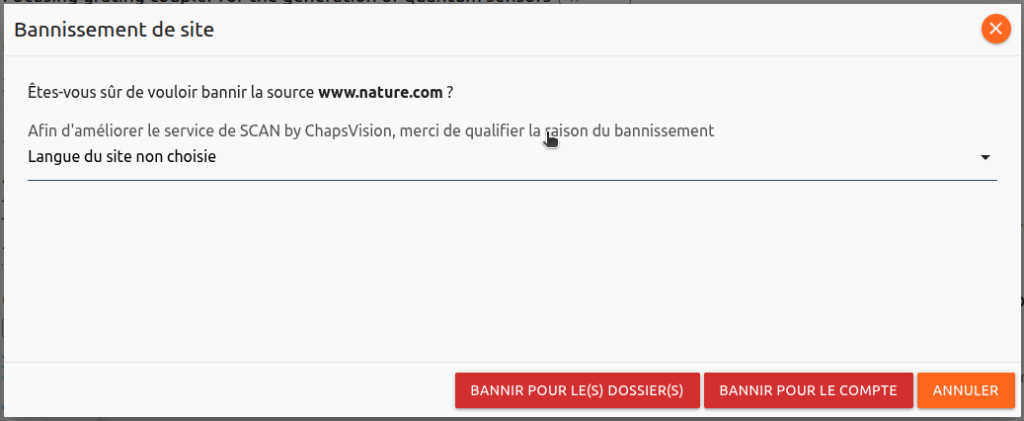
Vous pourrez bannir le site pour le dossier uniquement ou pour tout le compte en fonction du bouton de validation choisi (BANNIR POUR …) dans la fenêtre de bannissement. Si jamais vous avez banni un site par erreur, vous pourrez toujours le débannir via la page « Mon compte », rubrique « Sources bannies« .
Cas 4 : l’article ne date pas du jour indiqué ou date d’il y a longtemps
Il arrive qu’un article ait une date erronée. Malheureusement il arrive que certains sites diffusent leurs actualités avec des dates erronées ou trompeuses pour Scan. Parfois il peut même s’agir d’une « republication » soudaine d’anciennes actualités que Scan peut considérer comme nouvelles.
Vous pouvez supprimer l’article de votre dossier pour qu’il n’apparaisse plus, vous pouvez également signaler le problème au support ChapsVision (Cf. page Contact) pour qu’il fasse un correctif sur la source associée, ça pourra permettre d’empêcher le problème de se reproduire sur cette source.
Cas 5 : la requête matche avec le titre du site
On voit dans ce premier exemple que les articles (qui parlent de tout et de rien) matchent à chaque fois avec le titre du site :

On voit dans cet autre exemple que l’extrait qui matche la requête « quantum cryptography » (encadré en rouge) est trouvé à l’intérieur du titre du site (entouré en bleu) dans le « cartouche » de détails de l’article ouvert :
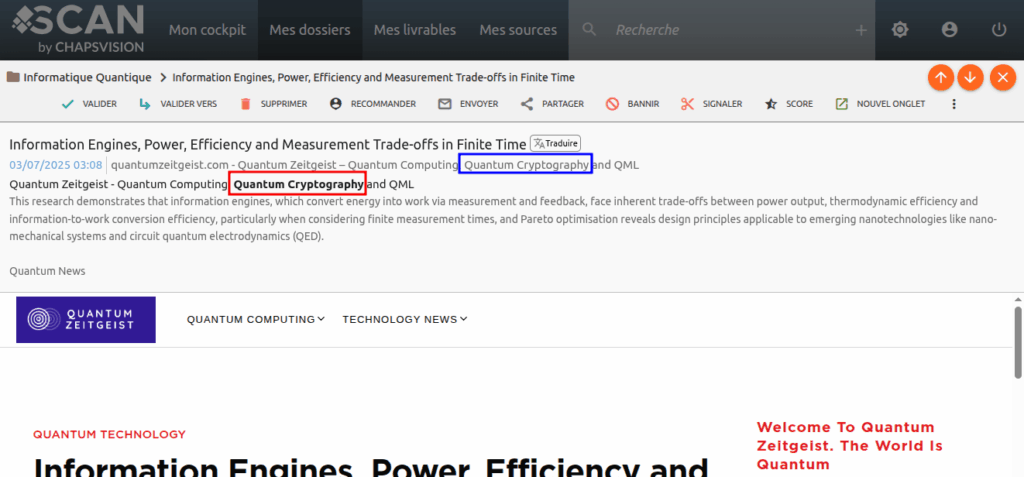
Scan permet de faire matcher les requêtes dans les champs titre/description/texte des actualités mais aussi dans les titres des sites.
On pourra :
- bannir le site si celui-ci ne ramène que des articles inintéressants.
- forcer sa requête sur les autres champs des articles : au lieu de chercher uniquement « quantum cryptography », on recherchera @(title,description,text) « quantum cryptography »
En mode « BLOCS », ça revient à cocher les trois options dans la liste suivante :
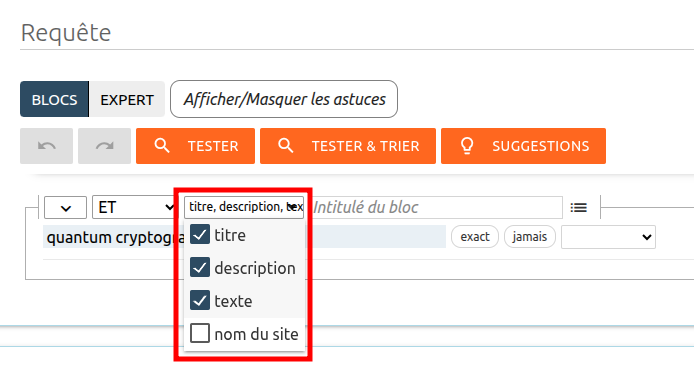
Vous pouvez également contacter le support ChapsVision (Cf. page Contact) pour qu’il corrige le nom du site si celui-ci vous paraît inapproprié ou erroné.